A few months ago, I was working on a project that required me to look through a lot of search results at the Corpus of LDS General Conference Talks. I was surprised to find that some speakers not only told the same stories and made the same points in multiple talks, they frequently used exactly the same phrasing in doing so. In other words, they were clearly copying and pasting parts from one talk to another. Not that I blame them. I know GAs are busy people, so in retrospect I probably shouldn’t have been surprised.
This got me to wondering, though, whether some Conference speakers use this copy-and-paste strategy more than others. I hit on an easy way to measure how often they do this while reading Brian Christian’s fascinating book The Most Human Human. The book is about the author’s preparation for participating in a Turing test, where his role is to serve as a chat partner for judges who are trying to distinguish between computer programs and people, and his goal is to win the award that is the book’s title, by convincing the most judges that he is a human and not a computer. One issue Christian discusses is redundancy in language. For example, when we’re reading, we can predict with accuracy far better than chance what word will come next in a sentence, and our accuracy goes up as the sentence goes on. More importantly for my purposes, compression software also works by spotting redundancies in language.
Compression software can be used to answer my question about which speakers are most redundant from one talk to another. But I quickly realized it could also be used to answer other questions of redundancy. For example, which speakers repeat themselves most within talks? Also, which speakers are most similar to one another? (The more redundant they are, the more similar they are.)
Method
To answer all these questions, I started by gathering plain text versions of all Conference talks given between 1971 and 2012. (And before you ask, yes, I even got a copy of that one that isn’t in the Conference Ensign.) I included all regularly-occurring sessions like Welfare Session and Women’s Session and Young Women’s Session and Relief Society Session, even though in some cases I realize these might not be considered to be officially part of Conference. The number of talks during this time period was 3,040, and the number of speakers who gave at least one talk was 407.
Once I had all the talks, I used the handy program 7-Zip to compress the talk files in various combinations to answer the different questions. I compressed all the files using 7-Zip’s 7z format. This was important because, unlike most compression formats, 7z allows for solid compression, which means that the compression process searches for redundancies both within files and between files. Compression software more typically exploits only redundancies within each file separately. I ran 7-Zip using the command line interface, and set the compression level to 5 (the default).
One issue that I ran into repeatedly in trying to measure redundancy is that compressibility is strongly related to length. Longer talks are more compressible than are shorter ones. This makes sense if you think about it: a lot of language is content-irrelevant words that we use regardless of what we’re talking about. A speaker will say is and and and the and of a lot whether she’s condemning mixing fabrics in your clothes or praising women for growing their hair long. So even though a longer talk probably covers more topics, it will be easier to compress than a shorter talk simply because the content-irrelevant words are used for all the topics, and this redundancy will be exactly what the compression software exploits.
In all the analyses I did, I adjusted for this association between compressibility and length, and I’ve ranked talks and speakers by how compressible the talks are, after adjusting for the length of the talk or talks. (For the statistically-oriented, I ran regressions predicting compressed size from original size and used the residuals as a percentage of the original size to rank talks and speakers. For all regression models, R2 > .98.)
Redundancy within talks
Here are the ten most internally redundant talks from the sample1.
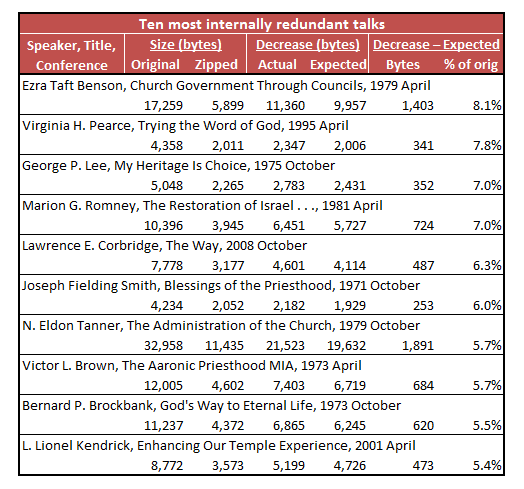
I’m sorry about the funny formatting. I am trying to fit a lot of information in and don’t have a whole lot of column width to work with. I also apologize for making the table an image so that it’s more difficult to re-size and you can’t change the font. I just had too much difficulty putting the table in HTML, so I resorted to images.
It’s not crucial to understand all the numbers in the table, but I’ve put them there in case you’re interested. Let me walk through an example to show you what the pieces are. The most internally redundant talk was Ezra Taft Benson’s “Church Government Through Councils.” The original file was 17,259 bytes. When I zipped the file, its size decreased to 5,899 bytes, a decrease of 11,360 bytes. But I had to adjust for the pattern I mentioned before, that longer talks are easier to compress than shorter ones are. Given the length of the talk, zipping it should have reduced its size by only 9,957 bytes (for the statistically oriented, this is the predicted value from the regression model estimated for the entire sample). The difference between the actual decrease in size from zipping and the expected decrease in size from zipping is 1,403 bytes. In other words, the talk declined in size 1,403 bytes more when zipped than would be expected based on its size alone. This size decrease beyond what was expected is 8.1% of the size of the original talk: 1,403 / 17,259 = 8.1%.
Here are the ten least internally redundant talks in the sample.
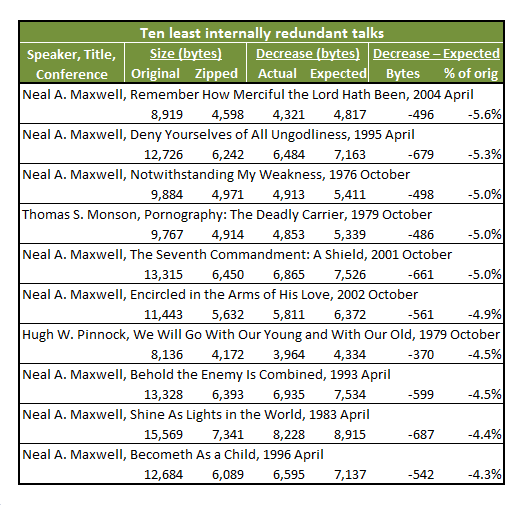 The calculations work the same as for the previous table. It’s interesting that Neal A. Maxwell has eight of the top ten. I guess this might have been expected given his reputation for using a more varied vocabulary than most speakers. His top ten performance is no fluke, either. He has 14 of the top 20, and 27 of the top 100 least redundant talks. The only other speaker who is close is Thomas S. Monson, who has 21 of the top 100.
The calculations work the same as for the previous table. It’s interesting that Neal A. Maxwell has eight of the top ten. I guess this might have been expected given his reputation for using a more varied vocabulary than most speakers. His top ten performance is no fluke, either. He has 14 of the top 20, and 27 of the top 100 least redundant talks. The only other speaker who is close is Thomas S. Monson, who has 21 of the top 100.
This line of discussion leads to another question: which speakers’ talks are most and least internally redundant on average? For this question, and all questions below about speakers, I’m going to use only the 67 speakers who gave at least ten talks in the sample. I’m doing this for two reasons. First, results are likely to be more reliable for speakers who have given more talks; it’s not very meaningful to talk about tendencies of speakers who have given only one or two talks. Second, it’s probably the speakers who have given a lot of talks that we’re more interested in, since they’re the ones we’re most familiar with.
Here are the 67 speakers who gave at least ten talks in the sample, ordered from highest to lowest average within-talk redundancy.
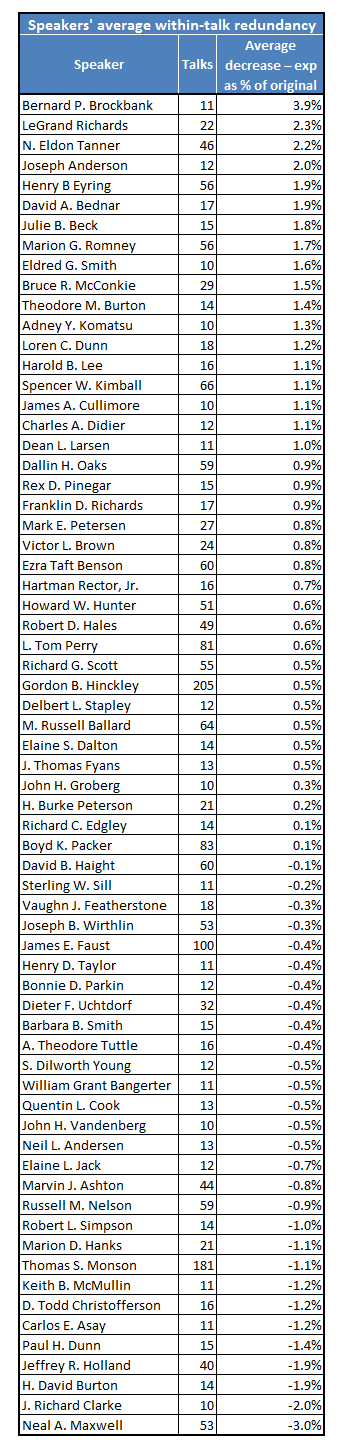
Elder Maxwell is by far the least internally redundant on average. The distance between him and #2 is the same as the distance between #2 and #11. At the other end, Bernard P. Brockbank is even more of an outlier. The distance between him and the #2 most internally redundant speaker is the same as the distance between #2 and #25.
Also, just looking at the talk counts, President Hinckley gave 205 Conference talks between 1971 and 2008. He accounts for well over 6% of talks in the sample all by himself. President Monson isn’t far behind at 181. Time will tell if he can catch President Hinckley, but giving several talks per Conference, he’s only a few years away.
Redundancy between talks
The next question is which speakers are most likely to repeat themselves from one talk to another, which was the original question that prompted this post. In answering this question, I wanted to avoid letting within-talk redundancy affect my estimates of between-talk redundancy. For each speaker (who gave at least ten talks), I zipped all their talks together into one file and compared the size of that file not to the sum of their original talk file sizes, but rather to the sum of the sizes of their individually zipped talk files. The difference in size between the original files and the individually zipped files captures within-talk redundancy, while the difference in size between the individually zipped files and the single zip file for all the speaker’s talks captures between-talk redundancy. (Note that this was where using solid archives was important because it allowed the program to exploit redundancies between files.)
Here are the 67 speakers who gave at least ten talks in the sample, ordered from highest to lowest between-talk redundancy.
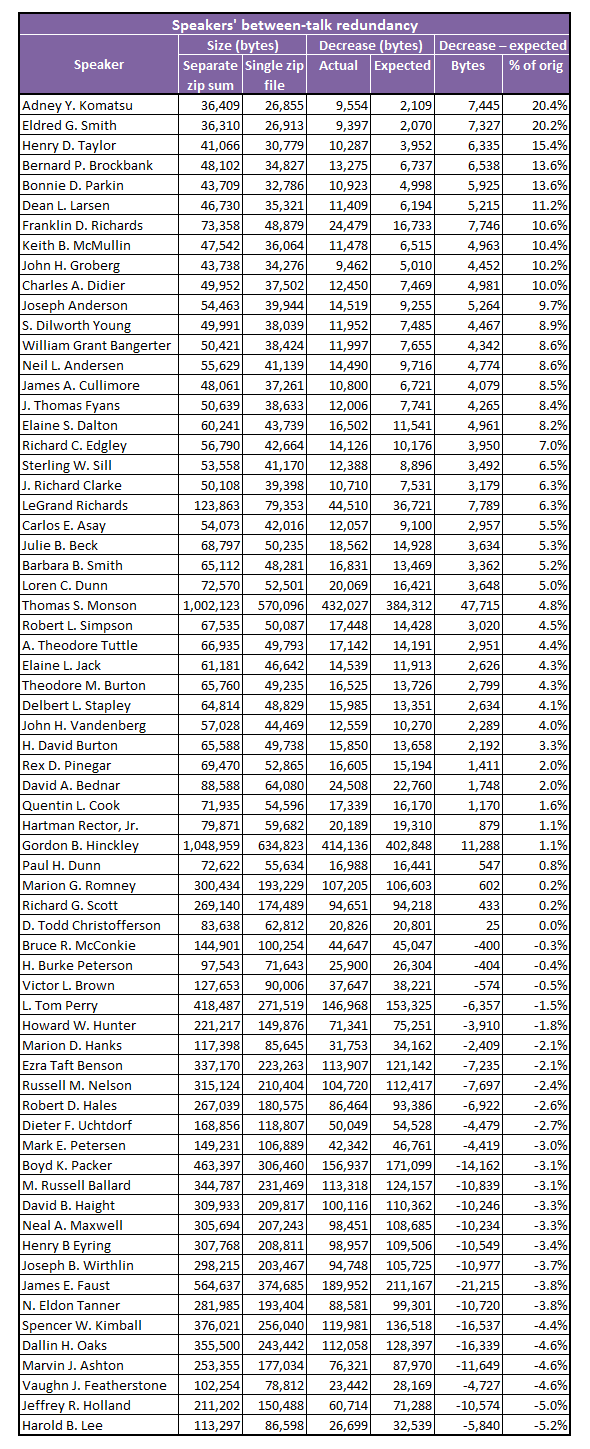
As before, you might not care about the numbers, but I’ll walk through an example in case you do. Harold B. Lee’s talks, when zipped separately, had a total file size of 113,297 bytes. When zipped together into one big file, the size of that file was 86,598 bytes. The difference is 26,699 bytes, the extra redundancy exploited by the program when it was able to zip the talk files together. Given the size of his individually zipped talks, though, a decrease of 32,539 bytes would be expected (for the statistically oriented, this is the predicted value from the regression model estimated for the 67 speakers). The difference is 5,840 bytes: zipping the talks together reduced file size by 5,840 bytes less than would be expected given the total size of the individually zipped talks. This size decrease beyond what was expected is 5.2% of the size of the sum of the individually zipped talks: 5,840 / 113,297 = 5.2%.
One pattern that might be interesting here is that the bottom of the table–the speakers who have the least between-talk redundancy–is dominated by members of the Quorum of 15. Vaughn J. Featherstone at #3 wasn’t a Q15 member, but you have to go all the way up to Victor L. Brown at #23 to find the next person who wasn’t. I suspect this means that Q15 members feel more free to address different topics that they see as important from one Conference to another, while Seventies and auxiliary leaders pretty much stick to the basics. If this is true, it might overshadow the tendency for some speakers to copy-and-paste their stories from one talk to another, although I do notice that President Monson, who is known for telling the same stories repeatedly, is higher in the table than any other Q15 member except for Franklin D. Richards, Neil L. Andersen and LeGrand Richards. Looking at the issue more systematically, the average percent difference from expected zip decrease (the last column in the table) for Q15 members is -0.9% and for non-Q15 members is 7.1%.
Conclusion
I don’t really have any grand conclusions, which I guess is a danger of starting without any hypotheses. 🙂 Thinking about the method, it’s clearly not the most valid measure of redundancy you could come up with. The zipping process is largely a black box; I understand it only in the most general terms. On the other hand, I’m encouraged that some of the patterns of results agree with intuition.
In the next post (or posts if I get too long-winded), I’ll look at similarity between speakers, as well as redundancy within and between entire Conferences.
Notes
1. I excluded from this analysis a few very short talks like the ones President Hinckley used to give when he was wrapping up Conference, because the association between length and compressibility suggested that their zipped sizes should be negative, which is of course impossible. I used 4,000 bytes as a cutoff (approximately 2 standard deviations below the mean length), and excluded all talks that were smaller than this in their original form, which was about 3.5% of all talks.
Curious results. I’ve actually been meaning to do some text analysis on a dataset like this. I know I could go get the data myself, but would you be willing to share it? (Mark Davies didn’t want to share his.) You know you want a McConkie sentence generator.
Interesting. This is offtopic, but I can’t help myself: Pres. Benson’s talk about governing the church through councils really caught my eye, given Benson’s conservative politics. The word “Soviet” actually means “council”, and the Soviet Union was indeed structured as a hierarchy of councils. I wonder how’s my people understood that this talk was encouraging the church to embrace ya Soviet side? =)
Interesting.
It appears that all 5 female speakers have above-median redundancy between talks, a rate that seems unlikely to be due to chance. Might this indicate that women speak (or are assigned to speak) on a narrower range of topics?
I’m trying to understand what level of text you were analyzing. I thought the goal was to look for redundancy at the paragraph, sentence, or even phrase level. But your example of “A speaker will say is and and and the and of a lot” makes me think you were looking at the redundancy of individual words? Thank you for any clarification.
Good question, HokieKate. It was the phrase level that caught my eye in the beginning. But the compression software is a pretty blunt tool, so I don’t really know what level most of its compression is working on. For example, I don’t know if most of the file size reduction comes from really common individual words, or somewhat common phrases, or even less common (but still repeated) sentences.
I guess you can file this under “weaknesses of the study.” 🙂 It’s kind of what I was trying to get at at the end: zipping is a reliable measure of redundancy, but it’s certainly not the most valid measure.
Could you look at average one talk redundancy vs age of the speaker? You have a pretty good database to look at the effects or non-effects of age.
It would be interesting to see how effective specialized compression software written especially for compressing conference talks would be.
Here is a link showing how 7-Zip does compared to best-in-class.
http://www.maximumcompression.com/data/text.php
Awesome! I think ziff should be a verb: to riff on church topics using statistical analysis. As in, I ziffed the quorum’s home teaching numbers and discovered that we’re not doing enough visits to the widows.
Love it, Mike C. I second the motion.
You need a calling…too much time on your hands
This is fantastic! Thanks for the time and energy to research and share with the rest of us.
Really? What part of a prophet, seer and revelator’s job is more important than addressing the world in the name of Jesus Christ?
I am sure this would be nearly impossible to figure out, but I am very curious about redundancy from one speaker to another, since so many talks quote previous talks, often at length.
Thanks, Mike and Galdralag and Melody. I think I’ve seen that suggested before, and I would be honored to have my name verbified. 🙂
Hannah, good idea. I’m actually hoping to put a speaker similarity measure in my next post.
Paul, looking at age is also a good idea. Unfortunately, I don’t already have it in the dataset, and it would take a little while to get it in, but I might see how difficult that would be.
This is the ziffiest ZD stats post yet, I am both in awe and struggling to remember anything from the three stats classes I was required to take long ago. I agree with Mike and Galdarag about using ziff as a verb!
I’ve got experience with linguistic analysis and have some tools that would give a better measure of redundancy than 7zip compression ratios. I’d really like to collaborate with you on a more rigorous analysis. Please send me an email; I’ve used my real email address for posting this comment.